𝗧𝗵𝗲 𝗠𝗲𝘁𝗿𝗶𝗰 𝘁𝗵𝗮𝘁 𝗠𝗮𝘁𝘁𝗲𝗿𝘀: Request Queue Time
Let's start by defining request queue time. It's basically how long a request has to "wait" before actual processing begins. This waiting usually happens at your application server after it has passed the reverse proxies and LBs and whatnot.
To understand why this happens, you can read this
𝗪𝗵𝘆 𝗶𝘀 𝗶𝘁 𝗶𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁?
Your p99 response time can be 200ms (yay), but if your queue time is 2s, the user will complain as he will receive the response after 2+0.2=2.2s. Quite simply, queue time shows the user impact of your server capacity.
Now the question is, 𝗵𝗼𝘄 𝗱𝗼 𝘆𝗼𝘂 𝗺𝗲𝗮𝘀𝘂𝗿𝗲 𝗶𝘁?
Most tools that measure request queue time use the X-Request-Start header added by the load balancer. Basically, you can get the time it crossed your LB to the time it got accepted for processing. Heroku adds this header automatically, AWS ELB on the other hand does not. So, if you are using ELB you will need to add this in your Ngnix or Ingress(or equivalent web server/reverse proxy).
For Ngnix it looks something like
𝚙𝚛𝚘𝚡𝚢_𝚜𝚎𝚝_𝚑𝚎𝚊𝚍𝚎𝚛 𝚡-𝚛𝚎𝚚𝚞𝚎𝚜𝚝-𝚜𝚝𝚊𝚛𝚝 "𝚝=${𝚖𝚜𝚎𝚌}";
After this, most APMs will automatically start tracking your queue time.
If your queue times are high, it's usually due to an under-provisioned infrastructure or fewer workers/threads. If it is low(< 20ms) you might be able to scale down a bit and save some $$.
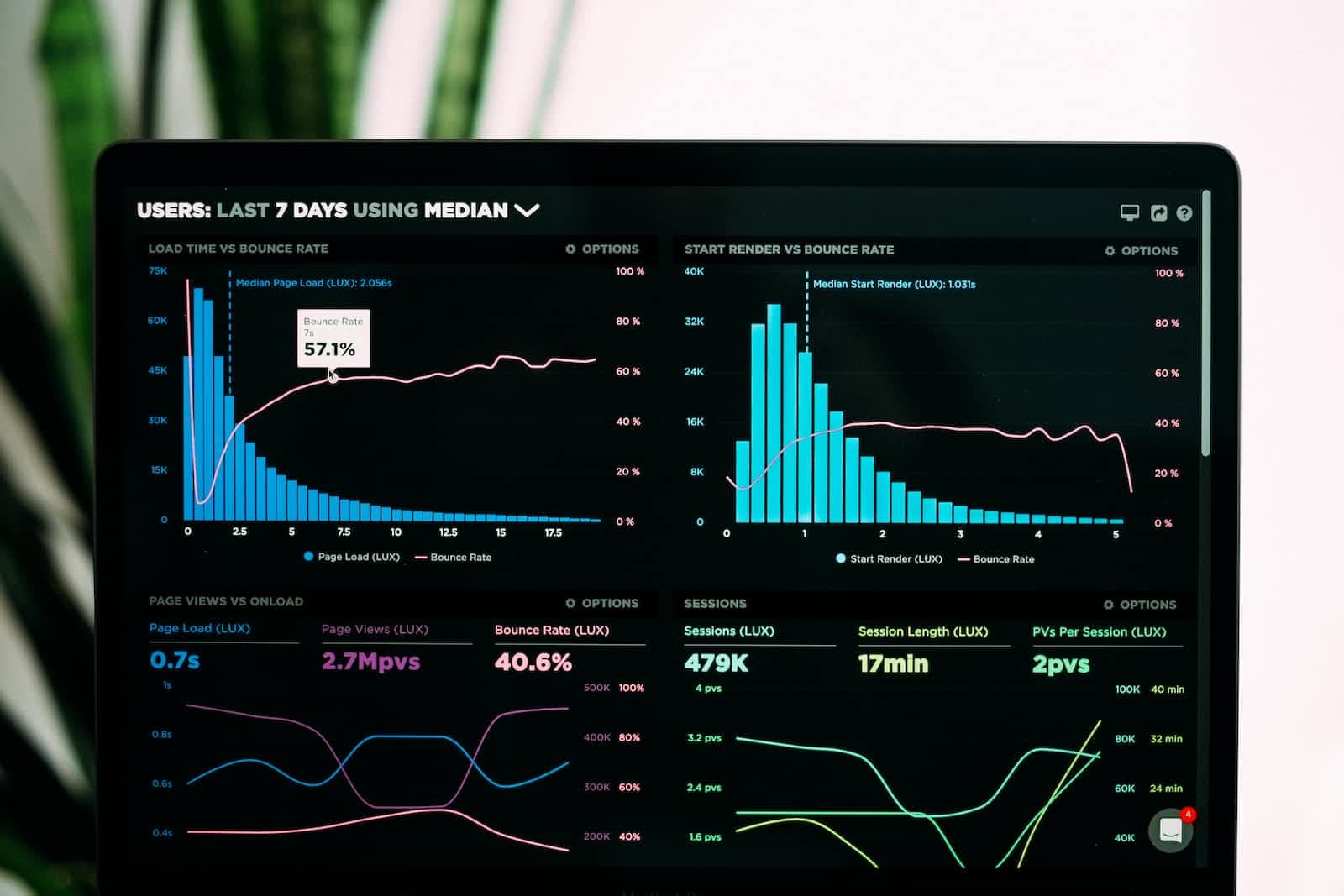
I have shared how and where you can check it in NewRelic below: